数据集成新增更多数据源支持 查看详情
数加 ・ 数据集成
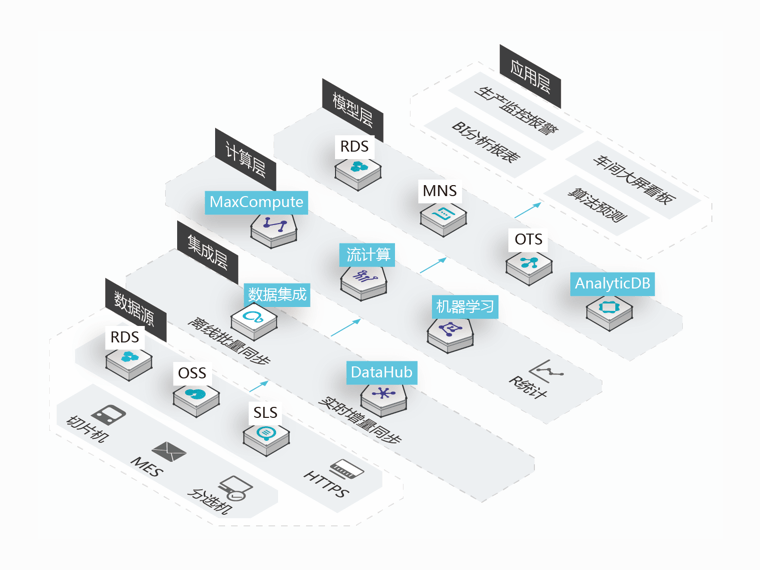
数据集成(Data Integration)是阿里集团对外提供的可跨异构数据存储系统的、可靠、安全、低成本、可弹性扩展的数据同步平台,为400对数据源提供不同网络环境下的全量/增量数据进出通道。
支持多种同步方式
同步任务调度和监控报警
支持经典/专有等网络环境
20+种异构数据源
同步任务调度和监控报警
支持多种同步方式
undefined
undefined
支持多种同步方式
支持经典/专有等网络环境
20+种异构数据源
undefined

-

20+种异构数据源
支持关系型数据库、大数据存储、非结构化存储、NoSql数据库之间的数据同步
-

支持经典/专有等网络环境
支持跨经典网络、专有vpc网络的数据同步以及本地IDC的数据同步
-

同步任务调度和监控报警
数据集成将会监控同步任务运行的状况并对异常进行报警
-
支持多种同步方式
通过where条件设定时间变量参数配合调度来实现增量数据同步
-
20+种异构数据源
支持关系型数据库、大数据存储、非结构化存储、NoSql数据库之间的数据同步
-
支持经典/专有等网络环境
支持跨经典网络、专有vpc网络的数据同步以及本地IDC的数据同步
-
同步任务调度和监控报警
数据集成将会监控同步任务运行的状况并对异常进行报警
-
支持多种同步方式
通过where条件设定时间变量参数配合调度来实现增量数据同步
精心打造的功能
-

支持多种异构数据源
数据集成支持20+种异构数据源之间的相互数据同步,通过数据源的Reader、Writer插件,无需用户实现复杂的编程


Reader&Writer插件
主要通过定义数据来源和去向的数据源和数据集,提供一套抽象化的数据抽取插件(称之为 Reader)、数据写入插件(称之为 Writer),并基于此框架设计一套简化版的中间数据传输格式,从而达到任意结构化、半结构化数据源之间数据传输之目的
抽取、转换、导入
数据集成支持在数据抽取过程中进行简单的数据转换操作(如日期解析、数据过滤等),导入到大数据处理中心,利用大数据引擎强大的计算能力可以再进行更复杂的数据转换操作
跨公网传输
支持天润智力经典网络、专有网络(VPC)环境下的数据同步以及本地IDC网络环境下的数据集成
-
支持多种同步方式
数据集成支持数据的批量(离线)同步,和增量同步
批量(离线)同步
批量同步主要应用场景为天润智力大数据计算存储(包括 MaxCompute、AnalyticDB 、HDFS等)提供离线(批量)的数据进出通道
增量同步
数据集成的增量同步主要是指通过where条件过滤业务日期,将不同业务日期的数据同步到对应的MaxCompute分区表中。用户可以通过设置同步周期为1小时一次或10分钟同步一次来实现近实时的增量同步
-
调度&监控告警
数据集成与大数据开发套件深度集成,完全复用开发套件的调度能力和同步任务运维能力
定时任务调度
数据集成支持多时间维度(天、小时、分钟)的离线任务定时调度,只需要简单几步便可完成数据增量抽取
任务出错报警
当任务出现错误的时候,数据集成支持通过预定义的方式告知用户任务失败。用户可以按照自己定义的规则来配置告警规则
-


整库迁移
整库迁移是数据集提供的一种批量创建同步任务的快捷工具,可以快速完成把一个Mysql DB 库内所有表一并上传到 MaxCompute 中,节省大量初始化批量任务创建时间
产品动态
数据集成客户实战场景
-

云数据库同步
-

数据回流分析
-

日志数据同步
-

异构数据源同步
-

精细化运营
PING++
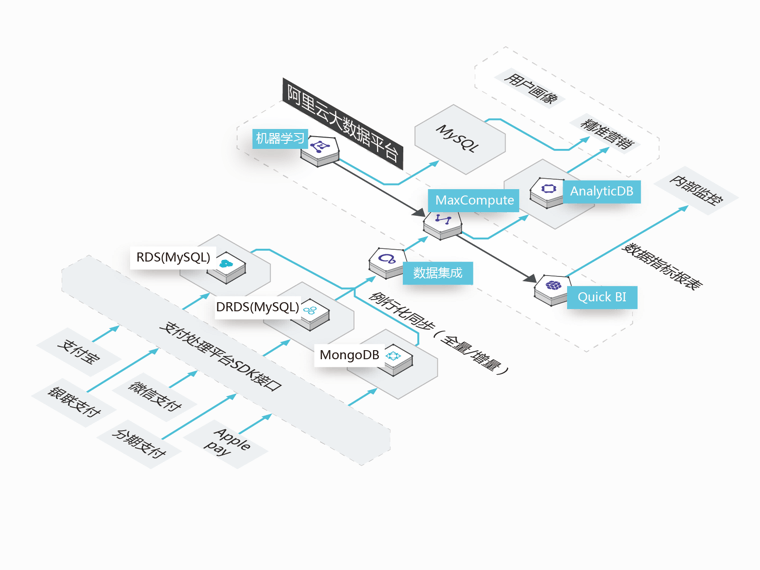
云数据库同步
Ping++的数据源主要来源于支付业务系统,DRDS和RDS主要用来存储用户交易信息,MongoDB主要用来存储商品维度信息;围绕这些积累下来的海量的交易数据,需要基于数加平台进行业务场景创新。
能够解决
-
数据批量同步
轻松实现积累的交易数据批量同步到大数据中心
-
定时增量同步
每日产生的交易数据可通过定时调度定时触发同步
-
出错告警易运维
当任务出现错误的时候,数据集成支持通过预定义的方式告知用户任务失败
推荐搭配使用
-
云数据库同步
PING++
Ping++的数据源主要来源于支付业务系统,DRDS和RDS主要用来存储用户交易信息,MongoDB主要用来存储商品维度信息;围绕这些积累下来的海量的交易数据,需要基于数加平台进行业务场景创新。
能够解决
-
数据批量同步
轻松实现积累的交易数据批量同步到大数据中心
-
定时增量同步
每日产生的交易数据可通过定时调度定时触发同步
-
出错告警易运维
当任务出现错误的时候,数据集成支持通过预定义的方式告知用户任务失败
-
-
数据回流分析
协鑫
智能制造的兴起,将大数据分析引入到制造革命中。通过对生产数据的采集并上传云端,可以对数据进行实时和长期分析,分析生成流程中可优化的部分
能够解决
-
日志数据同步
可以对协鑫光伏生产过程中采集到的全部日志数据同步到云端
-
异构数据源同步
数据集成提供四通八达的数据传输交互服务,可实现异构数据源之间的同步
-
任务按顺序执行
可将同步任务作为工作流一环,实现按顺序调度
-
-
日志数据同步
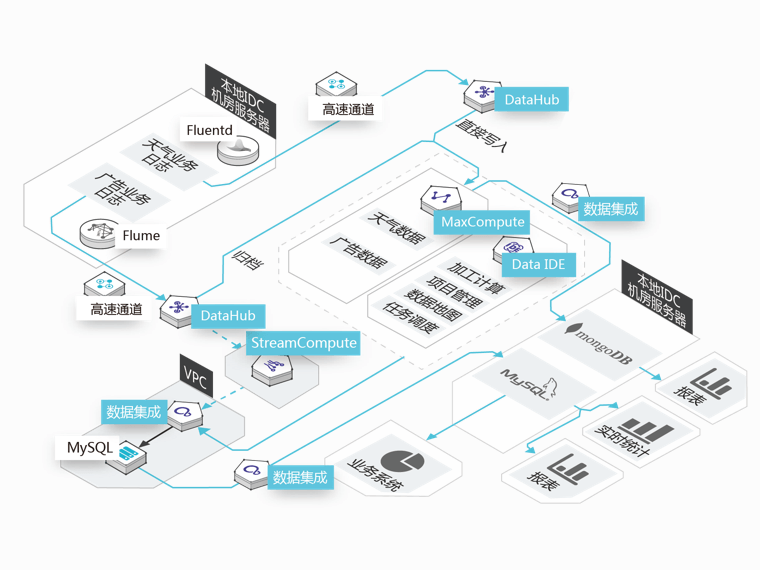
墨迹天气
墨迹天气运营团队每天处理分析庞大的天气查询以及广告业务日志,以分析用户行为和挖掘用户个性化需求, 亟需将数据集中到MaxCompute进行大数据分析,同时对数据传输集中工具也提出了更高的要求
能够解决
-
本地IDC数据同步
可使用插件进行日志采集,并同步归档到MaxCompute
-
数据回流
在MaxCompute分析完成的数据结果,可通过数据集成回流到业务库进行报表展现
-
传输速率
数据集成具有高效的调用方式、强劲的传输速度以及强大的吞吐能力
-
-
异构数据源同步
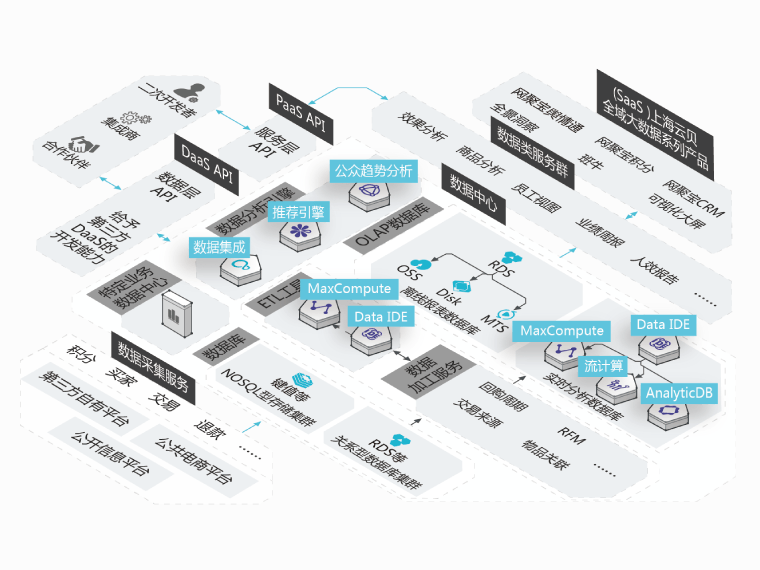
网聚宝
网聚宝的数据来源非常广泛,包括三大类数据源:第三方自有的平台、公共的电商平台、公开的信息平台, 如何通过数据采集服务分别将这些数据采集到数据中心是重点需要关注的问题
能够解决
-
消除数据孤岛
帮助企业将不同数据源的数据快速集中到数据中心
-
脏数据容错
可通过同步机制,在出现脏数据时做记录,但同步任务不会出错
-
定时任务调度
支持多时间维度的离线任务定时调度,只需要简单几步便可完成数据增量抽取
-
-
精细化运营
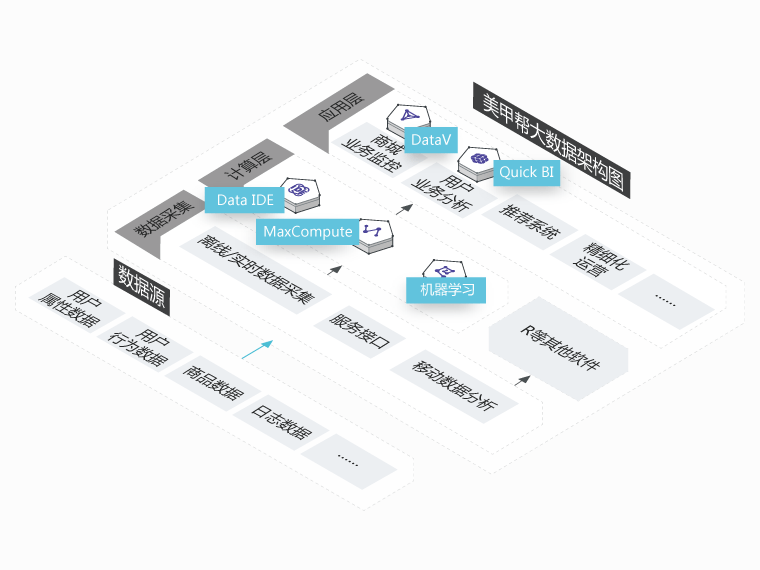
美甲帮
美甲帮的主营业务在商城方面,截至目前已经拥有百万级别的用户,积累了大量的用户数据,如何更好的服务用户并提升客户体验是美甲帮进行大数据探索的出发点
客户价值
-
提升业务洞察能力
通过MaxCompute计算能力实现了针对百万用户的精细化运营
-
业务数据化
对业务数据分析能力提升并有效监控,更好的业务赋能
-
快速响应业务需求
数加生态满足新业务数据分析需求的“随机应变”能力
-
数据集成支持的数据源
| 数据源类型 | 数据源 | 来源数据源 被读取 |
目标数据源 被写入 |
产品实现方式 |
|---|---|---|---|---|
天润智力数据库-关系型 |
MySQL SQL Server PostgreSQL |
支持 | 支持 | 向导方式/脚本方式 |
天润智力数据库-NoSQL |
Redis MongoDB HBase TableStore Memcache |
仅Redis&Memcache不支持 | 支持 | 脚本方式 |
关系型数据库 |
MySQL SQL Server PostgreSQL Oracle DRDS DB2 达梦(dm) |
支持 | 支持 | 向导方式/脚本方式 DB2和dm仅支持脚本模式 |
大数据存储 |
MaxCompute AnalyticDB OSS HDFS |
仅AnalyticDB不支持 | 支持 | 向导方式/脚本方式 HDFS仅支持脚本模式 |
非结构化存储 |
FTP |
支持 | 支持 | 向导方式/脚本方式 |
NoSql |
LogHub OpenSearch |
支持读loghub | 支持写opensearch | 脚本方式 |
性能测试 |
Stream |
支持 | 支持 | 脚本方式 |
数据集成视频教程

数据集成-产品简介

数据集成-同步模式

数据集成-支持的数据源

数据集成-增量同步

数据集成-整库迁移
x








 公安部备案号 11010502032413
公安部备案号 11010502032413









